Accueil Le chiffre de Che Le binaire et ASCII Mini Projet Projet
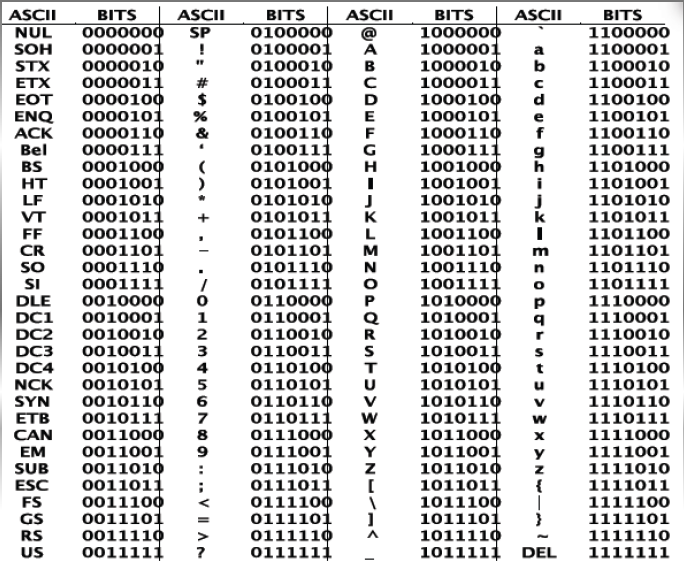
ASCII (American Standard Code for Information Interchange) = Code Americain Standard pour l'Echange d'Informations
Son principe est simple, il consiste à remplacer chaque lettres, caractères
du language courant, ou commande, par un code binaire, afin qu'il puisse être
lu par un ordinateur.
Il faut toutefois noter que ce language a été mis ne place pour la langue anglaise,
et donc qu'il ne contient pas de caractères accentués ni spécifique à un langue.
Ce language définit 128 caractères, codés en binaire de 00000000 à 11111111.
Les codes de 0 à 31 ne sont pas des caractères d'écriture. On les appelle caractères de contrôle car ils permettent de faire des actions telles que :
Les systèmes d'exploitation les plus récents utilisent le code ASCII étendu, ANSI, qui comprend les caractères accentués, ainsi que d'autres symboles.
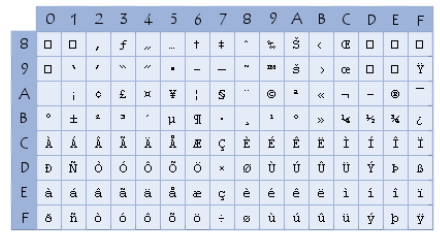
Pour faciliter les échanges entre les pays qui possèdent des caractères spèciaux
dans leur alphabet, un code plus pratique à été inventé : UNICODE.
Publié en 1991, il contient plus de 110 000 caractères, couvrant 100 écritures.
Malheureusement, il n'est pas tellement pratique, car il utilise des codes plus grands et
prend donc beaucoup plus de place.
Pour parer à ces désavantages, un autre codage à été inventé : UTF-8.
Ce language va combiner UNICODE et ASCII. Il utilisera principalement les caractères
de l'ASCII, mais utilisera le codage UNICODE dès qu'un caractère spécial sera demandé.
UTF-8 est donc plus efficace qu'UNICODE, car il prend beaucoup moins de place, mais il ne
permet pas le codage d'alphabet spéciaux.